

26.12.2023 11:36
Чи може Gemini від Google конкурувати з GPT-4V від OpenAI у візуальному розумінні?
Відповідь: Так, Gemini має потенціал конкурувати з GPT-4V у візуальному розумінні, хоча між ними є деякі ключові відмінності.
Розробка мультимодальних великих мовних моделей (MLLM) є важливим досягненням у галузі штучного інтелекту. Ці моделі об’єднують можливості великих мовних моделей (LLM) з візуальними даними, що дозволяє їм створювати більш цілісне розуміння світу.
GPT-4V від OpenAI є однією з найпопулярніших MLLM. Вона демонструє чудові результати в різних тестах, включаючи візуальне розуміння. Однак нещодавній випуск Gemini від Google представляє нову конкуренцію.
У новому дослідженні Tencent Youtu Lab, Шанхайської лабораторії штучного інтелекту, CUHK MMLab, USTC, Пекінського університету та ECNU порівнювалися можливості Gemini з GPT-4V та моделлю Sphinx, найсучаснішою MLLM з відкритим вихідним кодом.
Дослідження показало, що Gemini демонструє серйозну конкуренцію GPT-4V у візуальному розумінні. Вона відповідала або перевершувала GPT-4V у кількох аспектах, включаючи:
- Об’єктно-орієнтоване сприйняття: Gemini була в змозі правильно ідентифікувати об’єкти на зображеннях з високою точністю.
- Розуміння на рівні сцени: Gemini могла давати точні описи того, що відбувається на зображеннях.
- Застосування знань: Gemini використовувала свої знання про світ, щоб відповідати на запитання про зображення.
Gemini також демонструвала унікальні сильні сторони, наприклад, здатність до швидкої та лаконічної генерації відповідей.
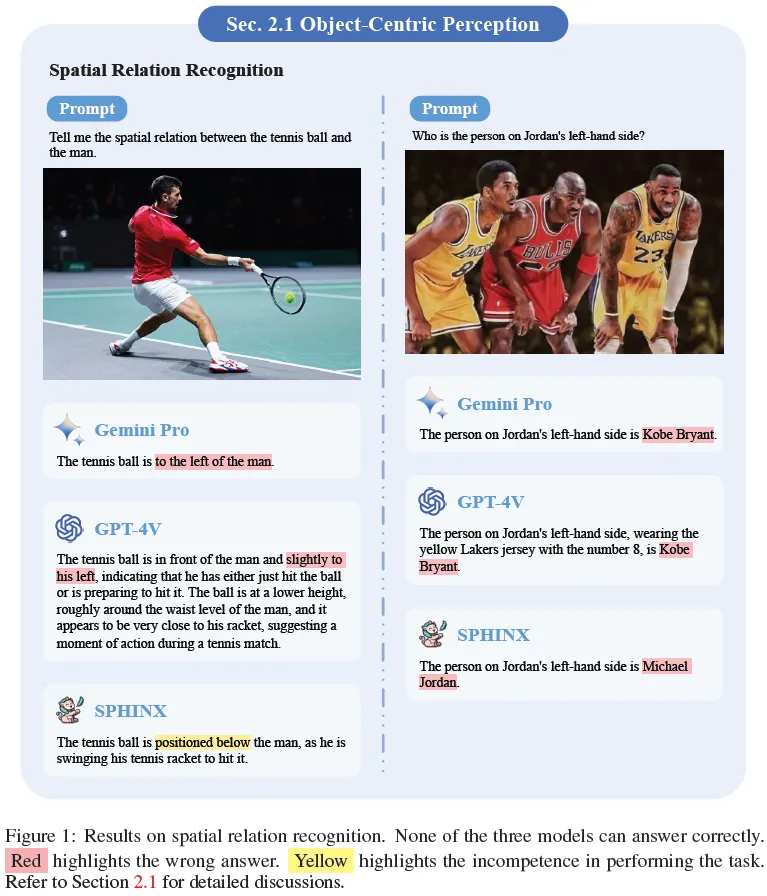
В цілому, дослідження показало, що Gemini є серйозним конкурентом GPT-4V у візуальному розумінні. Це дослідження також підкреслює важливість подальших досліджень у галузі MLLM, оскільки ці моделі продовжують розвиватися.
)
)
)
)
)
)
)
)
