

26.03.2024 11:27
16 змін у тому, як підприємства створюють і купують генеративний ШІ: Andreessen Horowitz
Генеративний ШІ захопив споживчий ландшафт у 2023 році, досягнувши понад мільярд доларів споживчих витрат за рекордно короткий час.
За останні кілька місяців співробітники Andreessen Horowitz поспілкувалися з десятками керівників компаній зі списку Fortune 500 і топменеджерів, а також опитали ще 70, щоб зрозуміти, як вони використовують, купують і виділяють кошти на генеративний ШІ.
Бюджети на генеративний ШІ стрімко зростають
У 2023 році середні витрати на API базової моделі, самостійне розміщення та тонке налаштування моделей становили $7 млн у десятках компаній, серед яких проводилося опитування. Більше того, майже кожне підприємство побачило багатообіцяючі перші результати експериментів з генеративним ШІ і планує збільшити свої витрати від 2 до 5 разів у 2024 році, щоб підтримати розгортання більшої кількості робочих навантажень у виробництві.
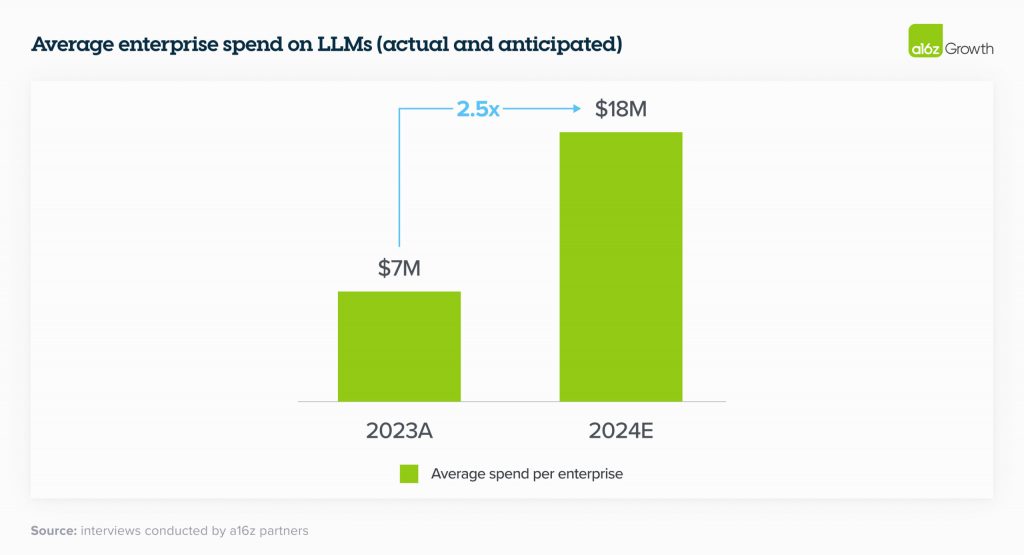
Керівники розпочинають перерозподіл інвестицій в ШІ на постійні статті бюджету для програмного забезпечення
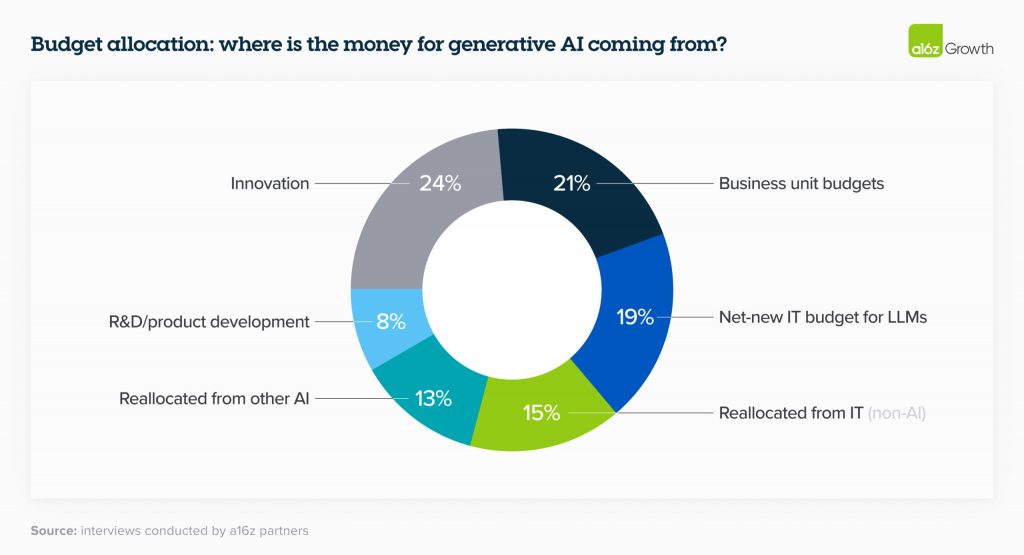
Минулого року значна частина корпоративних витрат на ШІ, що не дивно, надходила з «інноваційних» бюджетів та інших, як правило, одноразових фондів фінансування. Однак у 2024 році багато лідерів перерозподіляють ці витрати на більш постійні статті бюджету на програмне забезпечення; менше чверті повідомили, що цього року витрати на ШІ надходитимуть з інноваційних бюджетів. У значно менших масштабах деякі лідери розгортають свій бюджет на генеративний ШІ шляхом скорочення чисельності персоналу, особливо у сфері обслуговування клієнтів. Це може бути передвісником значно більших майбутніх витрат на генеративний ШІ, якщо ця тенденція збережеться. Одна компанія назвала економію близько $6 на кожному дзвінку, який обслуговує їхня служба підтримки клієнтів, що працює на базі LLM, — загалом близько 90% економії витрат — як причину збільшення інвестицій у генеративний ШІ у вісім разів.
Вимірювання рентабельності інвестицій — це і мистецтво, і наука
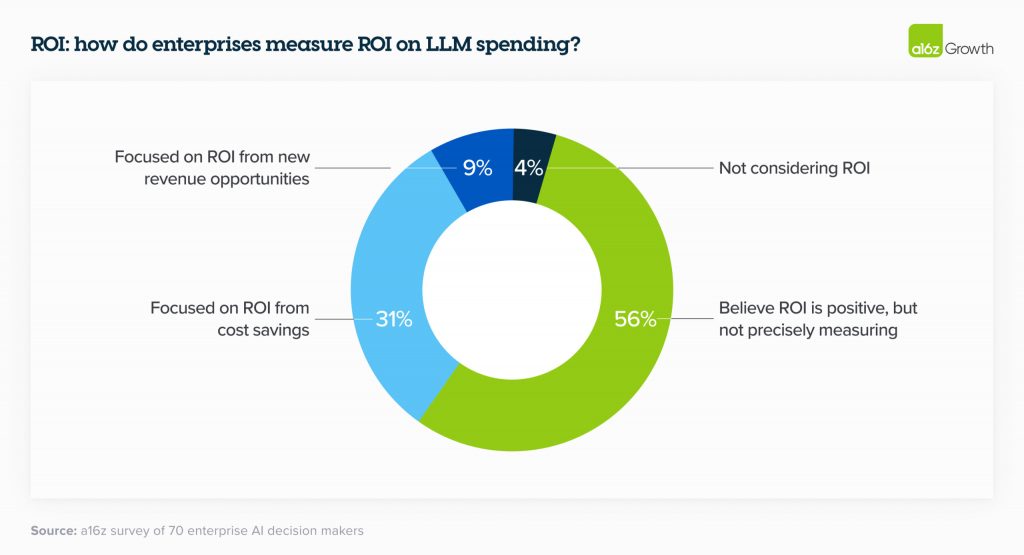
Наразі керівники підприємств здебільшого вимірюють рентабельність інвестицій шляхом підвищення продуктивності завдяки ШІ. Хоча вони покладаються на ІПС і задоволеність клієнтів як на хороші проміжні показники, вони також шукають більш відчутні способи вимірювання прибутку, такі як генерування доходу, економія, підвищення ефективності та точності, залежно від їхнього використання. У найближчій перспективі лідери все ще розгортають цю технологію і визначають найкращі показники для кількісної оцінки прибутку, але протягом наступних 2-3 років показник рентабельності інвестицій буде набувати все більшого значення. Поки керівники з’ясовують відповідь на це питання, багато хто сприймає на віру, коли їхні співробітники кажуть, що вони краще використовують свій час.
Впровадження та масштабування генеративного ШІ вимагає відповідних технічних талантів, яких наразі немає в штаті багатьох підприємств.
Просто мати API до постачальника моделей недостатньо для створення і розгортання рішень генеративного ШІ у великих масштабах. Потрібні вузькоспеціалізовані фахівці для впровадження, обслуговування та масштабування необхідної обчислювальної інфраструктури. Лише на впровадження припадає одна з найбільших статей витрат на ШІ у 2023 році, а в деяких випадках вона була найбільшою. Один з керівників зазначив, що «витрати на LLM, ймовірно, становлять чверть вартості створення кейсів використання», а витрати на розробку складають більшу частину бюджету.
Щоб допомогти підприємствам розпочати роботу на своїх моделях, постачальники фундаментальних моделей пропонували та продовжують надавати професійні послуги, як правило, пов’язані з розробкою моделей на замовлення. За оцінками Andreessen Horowitz, це становило значну частину доходу цих компаній у 2023 році та, окрім ефективності, є однією з ключових причин, чому підприємства обирали певних постачальників моделей. Оскільки знайти потрібних талантів у сфері генеративного ШІ на підприємстві дуже складно, стартапи, які пропонують інструменти, що полегшують розробку генеративного ШІ всередині компанії, скоріше за все, отримають швидший доступ до неї.
Мультимодельне майбутнє
Трохи більше ніж 6 місяців тому переважна більшість підприємств експериментували з 1 моделлю (зазвичай OpenAI) або максимум з 2. Сьогодні вони всі тестують — а в деяких випадках навіть використовують у виробництві — кілька моделей, що дозволяє їм:
- адаптуватися до конкретних випадків використання, виходячи з продуктивності, розміру та вартості;
- уникати прив’язки до однієї моделі;
- швидко використовувати досягнення в галузі, що швидко розвивається.
Третій пункт був особливо важливим для керівників, оскільки рейтинг моделей є динамічним, і компанії прагнуть використовувати як передові моделі, так і моделі з відкритим вихідним кодом, щоб отримати найкращі результати.
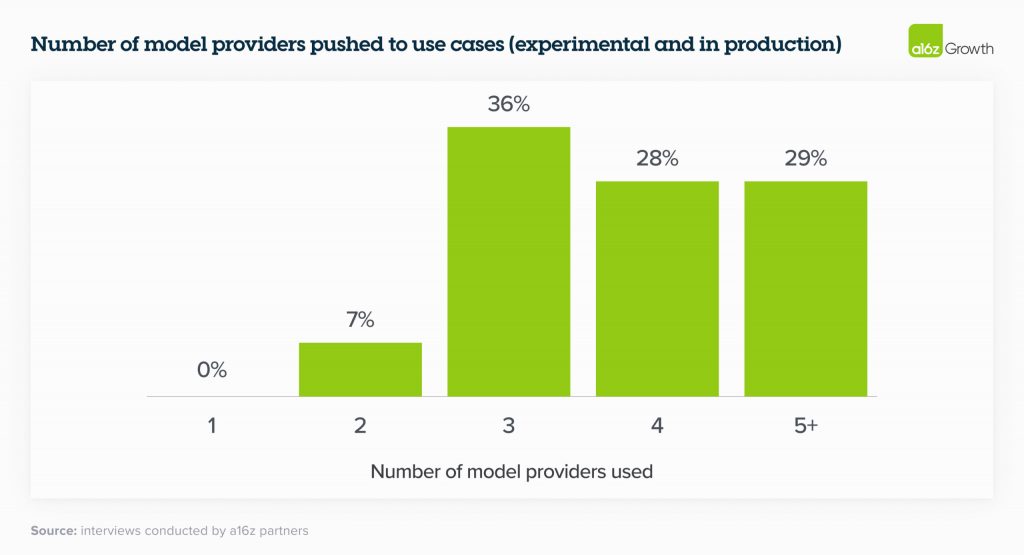
Ймовірно, ми побачимо ще більше моделей. У наведеній нижче таблиці, складеній на основі даних опитування, керівники підприємств повідомили про низку моделей у тестуванні, що є провідним показником моделей, які будуть використовуватися для передачі робочих навантажень у виробництво. Для виробничих випадків використання OpenAI, як і очікувалося, все ще має домінуючу частку ринку.
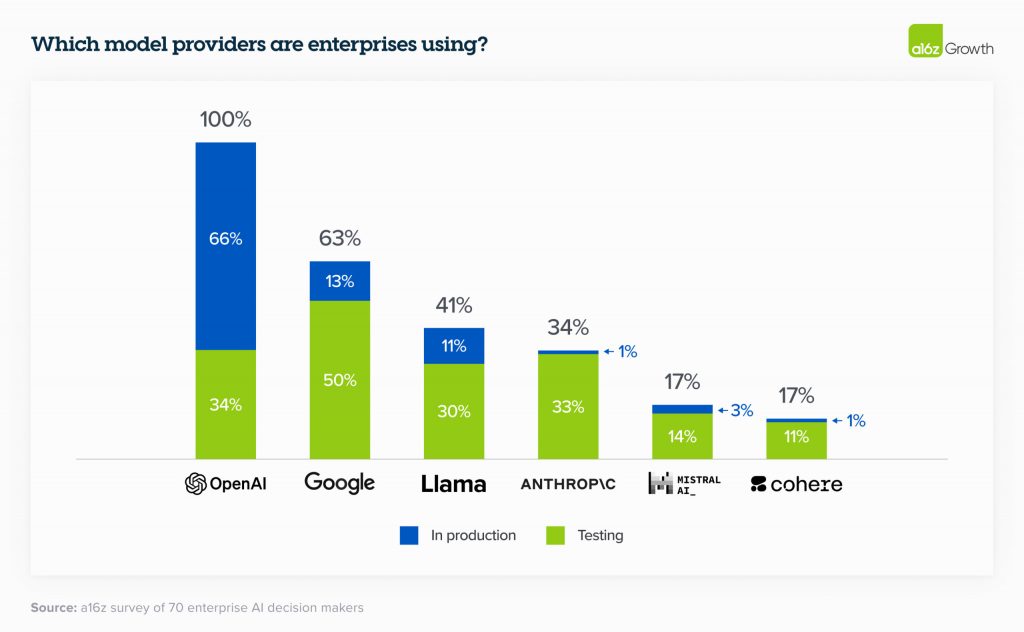
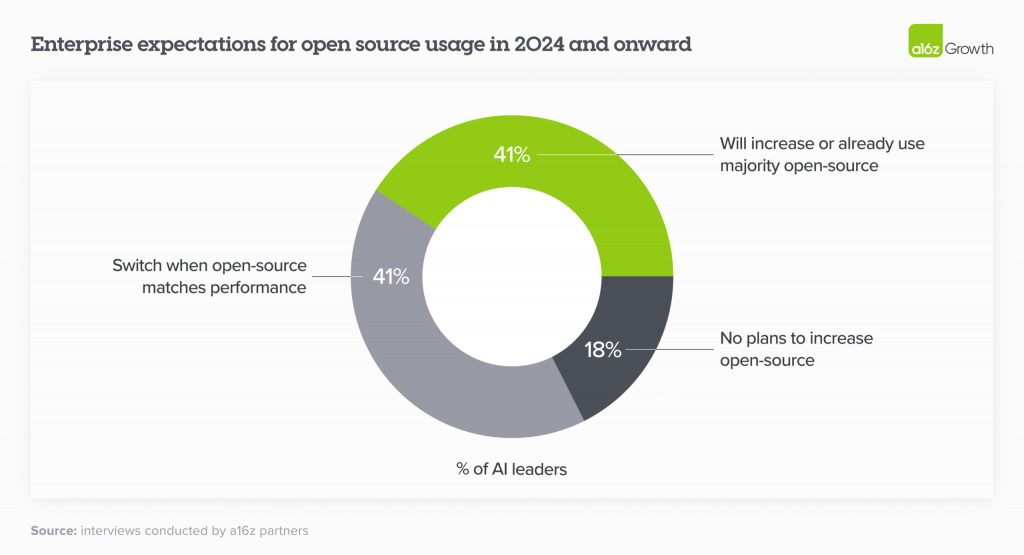
Відкрите програмне забезпечення на підйомі
Це одна з найдивовижніших змін у ландшафті за останні 6 місяців. За оцінками Andreessen Horowitz, частка ринку у 2023 році становила 80%-90% з закритим кодом, причому більшість частки припадала на OpenAI. Однак 46% респондентів опитування зазначили, що віддають перевагу або значною мірою віддають перевагу моделям з відкритим кодом у 2024 році. Під час опитування майже 60% лідерів ШІ-індустрії зазначили, що зацікавлені у збільшенні використання відкритого коду або переході на нього, коли доопрацьовані моделі з відкритим кодом будуть приблизно відповідати продуктивності моделей із закритим кодом. Таким чином, у 2024 році й далі підприємства очікують значного зсуву використання в бік відкритого коду, причому деякі з них прямо націлені на розподіл 50/50 з 80% закритого/20% відкритого коду у 2023 році.
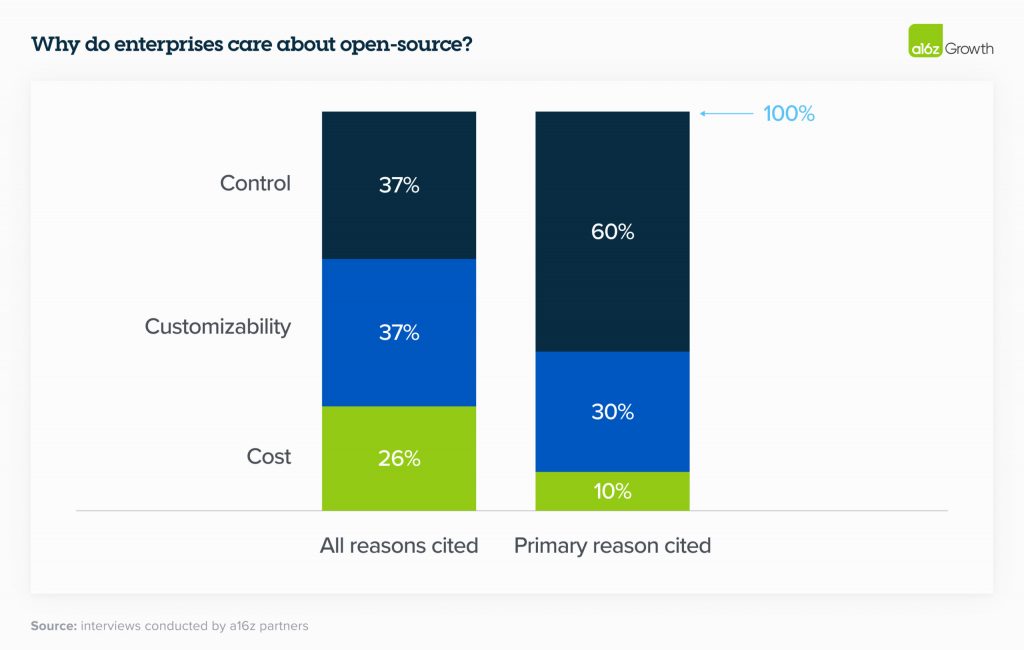
Хоча вартість впливає на привабливість відкритого коду, вона поступається контролю та кастомізації як ключовим критеріям вибору
Контроль (безпека власних даних і розуміння того, чому моделі дають певні результати) і кастомізація (можливість ефективного налаштування для конкретного випадку використання) значно переважали вартість як основні причини для прийняття відкритого коду. Співробітники Andreessen Horowitz були здивовані, що вартість не була на першому місці, але це відображає нинішнє переконання керівництва в тому, що надлишкова цінність, створена генеративним ШІ, швидше за все, набагато перевищить його ціну. Як пояснив один з керівників «отримання точної відповіді коштує грошей».
Прагнення до контролю зумовлене чутливими випадками використання та проблемами безпеки корпоративних даних
Підприємствам все ще некомфортно ділитися власними даними з постачальниками моделей із закритим кодом через регуляторні вимоги або проблеми безпеки даних — і не дивно, що компанії, чия інтелектуальна власність займає центральне місце в їхній бізнес-моделі, є особливо консервативними. У той час як деякі керівники розв’язали цю проблему, розмістивши власні моделі з відкритим кодом, інші зазначили, що надають перевагу моделям з інтеграцією у віртуальну приватну хмару (VPC).
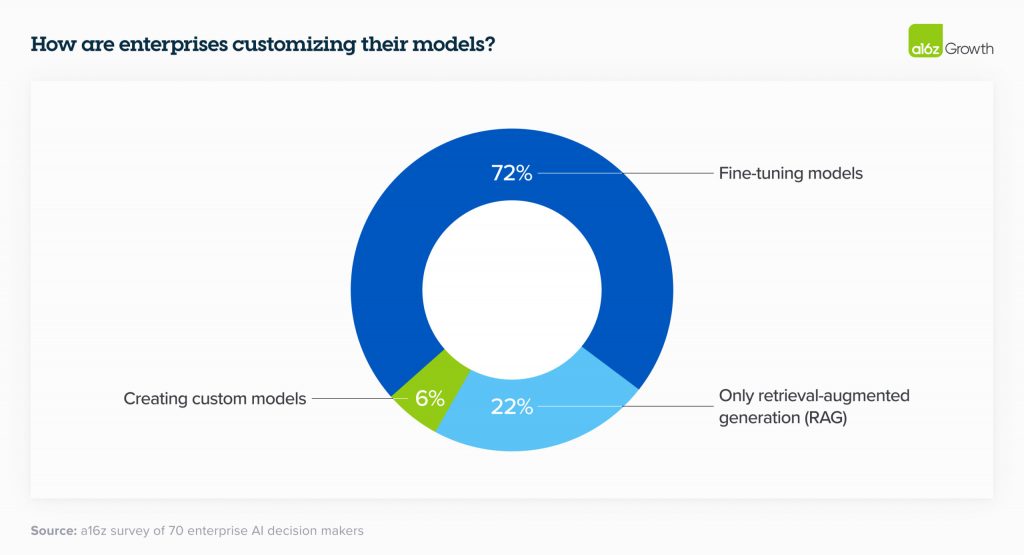
Лідери зазвичай кастомізують моделі шляхом точного налаштування, а не будують їх з нуля
У 2023 році було багато дискусій навколо побудови кастомних моделей, таких як BloombergGPT. У 2024 році підприємства все ще зацікавлені в кастомізації моделей, але з появою високоякісних моделей з відкритим вихідним кодом більшість вирішили не тренувати власні LLM з нуля, а замість цього використовувати генерацію, доповнену пошуком (RAG), або доопрацьовувати модель з відкритим вихідним кодом під свої конкретні потреби.
Хмара все ще має великий вплив на рішення про закупівлю моделей
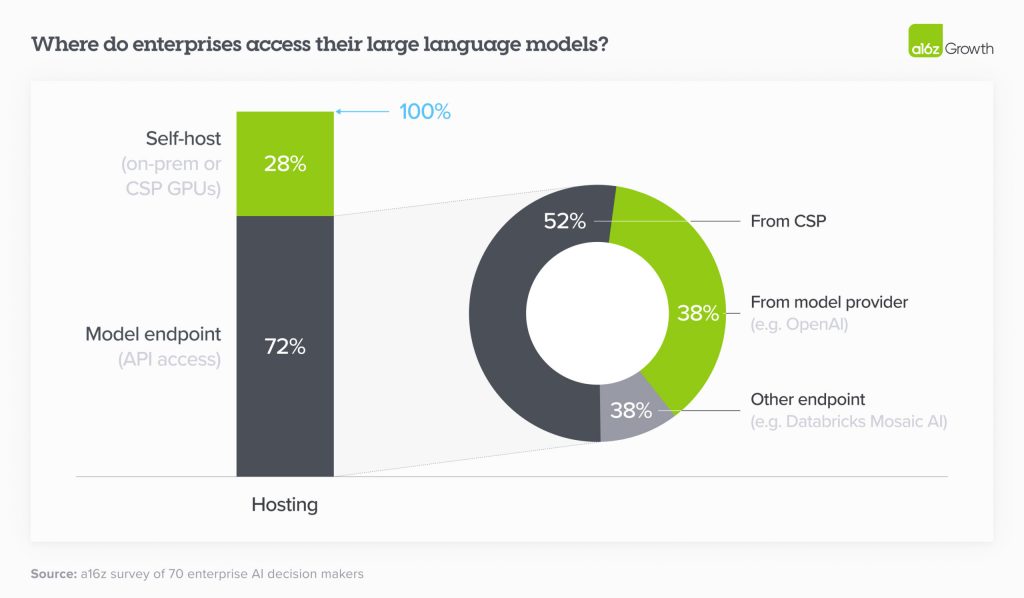
У 2023 році багато підприємств купували моделі через наявного постачальника хмарних послуг (CSP) з міркувань безпеки — керівники були більше стурбовані тим, що моделі з закритим кодом можуть неправильно обробляти їхні дані, ніж їхні CSP, — і щоб уникнути тривалих процесів закупівель. У 2024 році це все ще так, а це означає, що кореляція між CSP та моделлю, якій надається перевага, є досить високою: Користувачі Azure загалом віддавали перевагу OpenAI, тоді як користувачі Amazon — Anthropic або Cohere. Як можна побачити на графіку нижче, з 72% підприємств, які використовують API для доступу до своєї моделі, більша частина використовували модель, розміщену в їхньому CSP. (Слід зазначити, що понад чверть респондентів використовували власний хостинг, ймовірно, для того, щоб запускати моделі з відкритим кодом).
Клієнтів все ще цікавлять особливості раннього виходу на ринок
Хоча лідери називали можливість аргументації, надійність і простоту доступу (наприклад, на своєму CSP) як головні причини прийняття тієї чи іншої моделі, лідери також тяжіли до моделей з іншими диференційованими функціями. Наприклад, багато лідерів назвали 200-тисячне контекстне вікно ключовою причиною вибору Anthropic, тоді як інші обрали Cohere через його ранній вихід на ринок, просту у використанні пропозицію тонкого налаштування.
Однак, більшість підприємств вважають, що продуктивність моделей вирівнюється
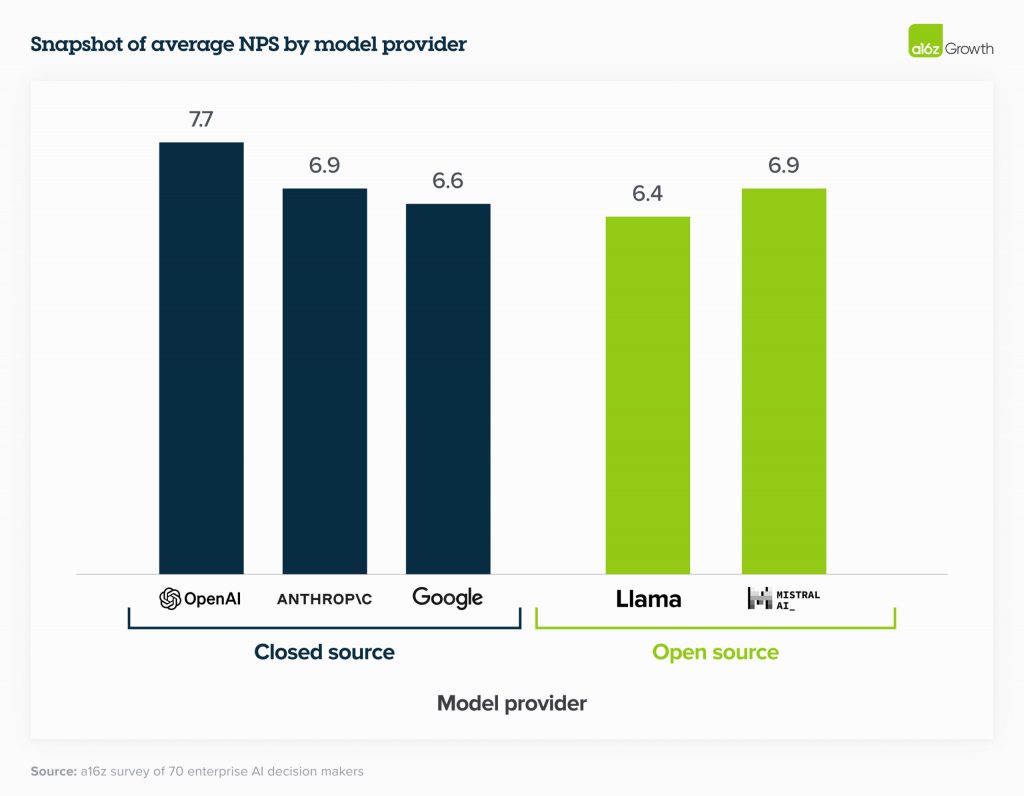
У той час як значна частина технологічної спільноти зосереджена на порівнянні продуктивності моделей з публічними бенчмарками, керівники підприємств більше зосереджені на порівнянні продуктивності доопрацьованих моделей з відкритим кодом і доопрацьованих моделей з закритим кодом з їхніми власними внутрішніми наборами бенчмарків. Цікаво, що попри те, що моделі з закритим кодом, як правило, показують кращі результати в зовнішніх тестах, керівники підприємств все одно дають моделям з відкритим кодом відносно високі показники ІПС (а в деяких випадках і вищі), оскільки їх легше налаштувати під конкретні випадки використання. Одна компанія виявила, що «після доопрацювання Mistral і Llama працюють майже так само добре, як OpenAI, але коштують набагато дешевше». За цими стандартами, продуктивність моделей вирівнюється навіть швидше, ніж очікувалось, що дає лідерам ширший вибір дуже потужних моделей на вибір.
Оптимізація для розширення можливостей
Більшість підприємств розробляють свої додатки таким чином, щоб перемикання між моделями вимагало не більше, ніж зміни API. Деякі компанії навіть проводять попереднє тестування підказок, щоб зміна відбувалася буквально одним натисканням кнопки, тоді як інші створюють «сади моделей», з яких вони можуть розгортати моделі в різних додатках за потреби. Компанії застосовують цей підхід частково тому, що вони засвоїли важкі уроки хмарної ери про необхідність зменшити залежність від провайдерів, а частково тому, що ринок розвивається так швидко, що нерозумно прив’язуватися до одного постачальника.
Підприємства створюють, а не купують додатки — поки що
Підприємства в переважній більшості зосереджені на створенні додатків власними силами, посилаючись на відсутність перевірених у боях, бездоганних корпоративних додатків для штучного інтелекту як на один із чинників, що спонукають до цього. Зрештою, для таких додатків не існує магічних квадрантів (поки що!). Фундаментальні моделі також спростили для підприємств створення власних програм штучного інтелекту, пропонуючи інтерфейси API. Наразі підприємства створюють власні версії звичних сценаріїв використання, таких як підтримка клієнтів і внутрішні чат-боти, а також експериментують з більш новими сценаріями використання, такими як написання рецептів споживчих товарів, звуження поля для відкриття молекул і надання рекомендацій з продажу. Багато написано про обмежену диференціацію «обгорток GPT» або стартапів, які створюють знайомий інтерфейс (наприклад, чат-бот) для добре відомого результату LLM (наприклад, узагальнення документів); одна з причин, чому вважається, що вони будуть боротися, полягає в тому, що штучний інтелект ще більше знизив бар’єр для створення подібних додатків власними силами.
Однак журі все ще не визначилося, чи зміниться ситуація, коли на ринку з’явиться більше додатків зі штучним інтелектом, орієнтованих на підприємства. Один із лідерів зазначив, що, хоча вони розробляють багато прикладів використання ШІ власними силами, вони оптимістично налаштовані на те, що «з’являться нові інструменти», і вважають за краще «використовувати найкраще з того, що є на ринку». Інші вважають, що генеративний ШІ стає все більш «стратегічним інструментом», який дозволяє компаніям впроваджувати певні функціональні можливості власними силами замість того, щоб покладатися на зовнішніх постачальників, як це було традиційно. Враховуючи цю динаміку, у Andreessen Horowitz вважають, що додатки, які виходять за рамки формули «LLM + UI» і суттєво переосмислюють основні робочі процеси на підприємствах або допомагають підприємствам краще використовувати власні дані, будуть особливо успішними на цьому ринку.
Підприємства зацікавлені у внутрішніх сценаріях використання, але залишаються більш обережними щодо зовнішніх
Це пов’язано з тим, що 2 основні проблеми, пов’язані з генною інженерією, все ще залишаються актуальними для підприємств:
- потенційні проблеми з галюцинаціями та безпекою;
- проблеми зі зв’язками з громадськістю, пов’язані з впровадженням генеративного ШІ, особливо в чутливих споживчих секторах (наприклад, у сфері охорони здоров’я та фінансових послуг).
Найпопулярніші випадки використання минулого року були або зосереджені на внутрішній продуктивності, або проходили через людину, перш ніж потрапити до клієнта — копілоти для кодування, підтримка клієнтів і маркетинг. Як можна побачити на графіку нижче, ці варіанти використання все ще домінують на підприємствах у 2024 році, причому підприємства просувають повністю внутрішні варіанти використання, такі як узагальнення тексту та управління знаннями (наприклад, внутрішній чат-бот), до виробництва набагато швидше, ніж чутливі варіанти використання, що потребують участі людини, такі як перегляд контрактів, або варіанти використання, орієнтовані на клієнта, такі як зовнішні чат-боти або алгоритми рекомендацій. Компанії прагнуть уникнути наслідків генеративних невдач зі штучним інтелектом, на кшталт провалу в обслуговуванні клієнтів авіакомпанії Air Canada. Оскільки ці проблеми все ще залишаються актуальними для більшості підприємств, стартапи, які створюють інструменти, що допомагають контролювати ці проблеми, можуть отримати значне поширення.

До кінця 2024 року загальні витрати на модельні API та доопрацювання зростуть до понад $5 млрд, і значну частину з них становитимуть витрати підприємств
За підрахунками Andreessen Horowitz, ринок модельних API (включно з тонким налаштуванням) на кінець 2023 року становитиме близько 1,5-2 млрд доларів США, включаючи витрати на моделі OpenAI через Azure. Враховуючи очікуване зростання загального ринку та конкретні показники підприємств, витрати лише на цю сферу до кінця року зростуть щонайменше до $5 млрд зі значним потенціалом для подальшого зростання. Як вже обговорювалось, підприємства надали пріоритет розгортанню генеративного ШІ, збільшили бюджети та перерозподілили їх на стандартні лінійки програмного забезпечення, оптимізували сценарії використання різних моделей і планують передати ще більше робочих навантажень на виробництво у 2024 році, а це означає, що вони, ймовірно, забезпечать значну частку цього зростання.
За останні 6 місяців підприємства видали низхідний мандат на пошук і розгортання рішень генеративного ШІ. Угоди, на закриття яких раніше йшло понад рік, укладаються за 2-3 місяці, і ці угоди набагато більші, ніж у минулому.
Нагадаємо, у грудні Andreessen Horowitz заявила, що буде вкладати гроші в політиків, які підтримують її бачення оптимістичного майбутнього, засноване на технологіях.
)
)
)
)
)
)
)
)
