

27.02.2024 10:40
Magic-Me від ByteDance, фреймворк для створення індивідуально ідентифікованих відео
Дослідники з ByteDance Inc. та Каліфорнійського університету в Берклі розробили Video Custom Diffusion (VCD) — просту, але потужну платформу для створення відео з контрольованою ідентичністю суб’єкта.
VCD використовує три ключові компоненти: модуль ідентифікації для точного виділення ідентифікаційних даних, 3D-гауссівський шумопоглинач для узгодженості між кадрами та модулі V2V для покращення якості відео. Виокремлюючи ідентифікаційну інформацію з фонового шуму, VCD точно вирівнює ідентифікатори, забезпечуючи стабільний вихідний відеосигнал.
Гнучкість фреймворку дозволяє йому безперешкодно працювати з різними моделями контенту, створеними штучним інтелектом. Серед досягнень — значний прогрес у створенні відео для ідентифікації, надійні методи зашумлення, покращення роздільної здатності та навчальний підхід до зменшення шуму в ідентифікаційних токенах.

У генеративних моделях досягнення T2I-генерації призвели до створення кастомізованих моделей, здатних створювати реалістичні портрети та творчі композиції. Такі методи, як текстова інверсія та DreamBooth, допрацьовують попередньо навчені моделі за допомогою зображень певних предметів, генеруючи унікальні ідентифікатори, пов’язані з потрібними об’єктами. Цей прогрес поширюється і на багатооб’єктну генерацію, коли моделі вчаться компонувати кілька об’єктів в одне зображення.
Перехід до генерації T2V створює нові виклики через необхідність просторової та часової узгодженості між кадрами. У той час як ранні методи використовували GAN і VAE для відео з низькою роздільною здатністю, останні підходи використовують моделі дифузії для отримання більш якісного результату.
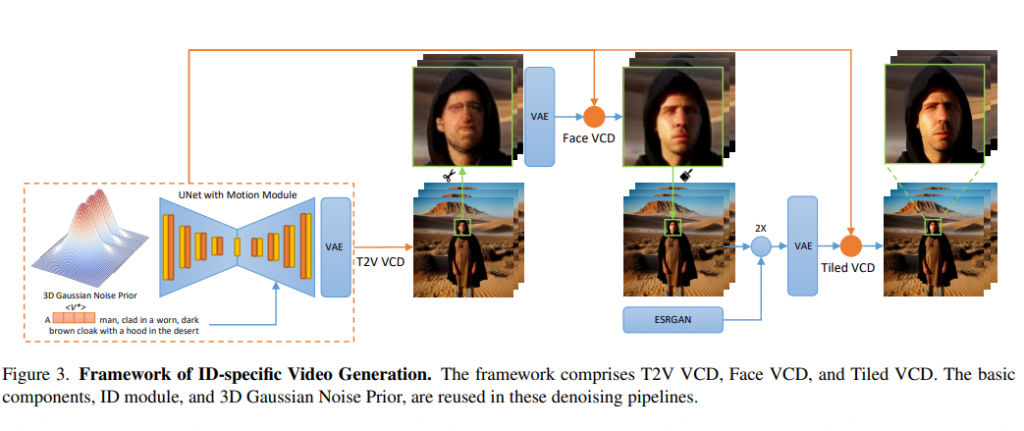
У фреймворку VCD використовуються модуль попередньої обробки, модуль ідентифікації та модуль руху. Крім того, додатковий модуль ControlNet Tile здійснює вибірку відео для отримання вищої роздільної здатності. VCD покращує стандартний модуль руху за допомогою 3D-гауссового шуму перед зменшенням похибки експозиції під час висновку.
Модуль ідентифікації включає розширені маркери ідентифікації з маскованими втратами та швидкою сегментацією, що ефективно усуває фоновий шум. У дослідженні також згадуються два конвеєри V2V VCD: Face VCD, який покращує риси обличчя і роздільну здатність, і Tiled VCD, який ще більше збільшує масштаб відео, зберігаючи деталі ідентифікації. Ці модулі разом забезпечують створення високоякісного відео зі збереженням ідентичності.
Модель VCD зберігає ідентичність персонажів у різних реалістичних і стилізованих моделях. Дослідники ретельно відбирали суб’єктів з різних наборів даних і оцінювали метод у порівнянні з кількома базовими лініями, використовуючи CLIP-I та DINO для вирівнювання ідентичності, вирівнювання тексту і часової згладженості. Деталі навчання включали використання Stable Diffusion 1.5 для модуля ідентифікації та відповідне коригування швидкості навчання і розмірів партій.

У дослідженні були використані дані з наборів даних DreamBooth і CustomConcept101 та оцінена ефективність моделі за різними метриками. Дослідження підкреслило вирішальну роль модуля 3D-гауссівого шумоподавлення та швидкої сегментації в покращенні плавності відео та вирівнюванні зображення. Реалістичне бачення загалом перевершило стабільну дифузію, що підкреслює важливість вибору моделі.
Нагадаємо, у січні ByteDance представила новий метод створення відео з текстових описів під назвою MagicVideo-V2.
)
)
)
