

15.02.2024 09:57
Дослідники компанії NVIDIA представили нову модель аудіо-мови під назвою Audio Flamingo
В галузі дослідження розширення великих мовних моделей (LLM) на аудіо-сферу, що включає розуміння немовних звуків та невербальної мови, спостерігається стрімкий розвиток. Ці дослідження ставлять за мету розширити можливості застосування LLM від систем, що реагують на голос, до складних інструментів аудіоаналізу. Однак, виникає виклик у створенні моделей, які можуть ефективно обробляти аудіо-сигнали, включаючи не лише просту транскрипцію мовлення, а й розпізнавання широкого спектра звуків, таких як музика, звуки навколишнього середовища та невербальні вокалізації.
Сучасні дослідження зазвичай фокусуються на транскрибуванні мовлення або ідентифікації окремих звуків у аудіофайлах. Використання методів, таких як згорткові нейронні мережі (CNNs) та трансформатори, дозволяє виділяти аудіо-характеристики, але часто вимагає більш довготривалих обчислень. Для покращення адаптивності моделей використовуються стратегії доповнення даних та навчання в контексті (ICL). Зокрема, генерація, доповнена пошуком (RAG), використовує зовнішні знання для поліпшення якості вихідних даних. Це підкреслює різноманітність підходів для розуміння LLM у різних модальностях.
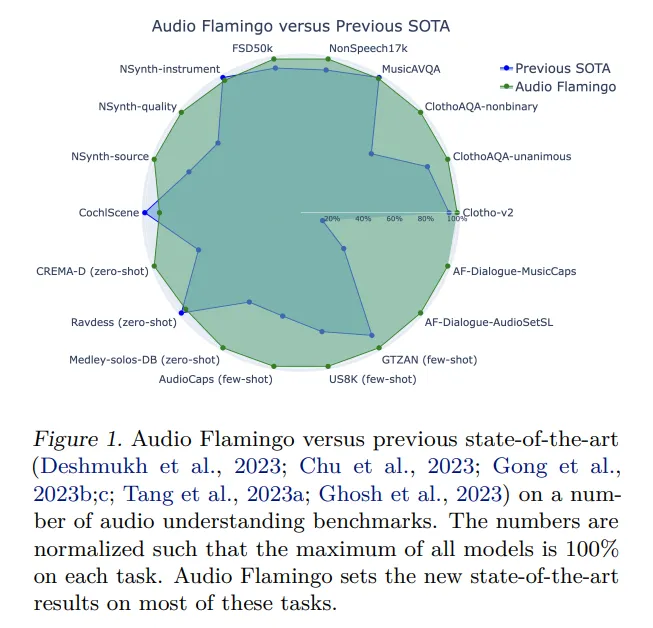
Команда дослідників від NVIDIA представила модель Audio Flamingo, яка володіє покращеним розумінням аудіо, швидким адаптивним навчанням і ефективним керуванням діалогами. Завдяки унікальним методам навчання, архітектурним інноваціям та стратегічному використанню даних, Audio Flamingo покращує продуктивність виконання різноманітних завдань аудіоаналізу.
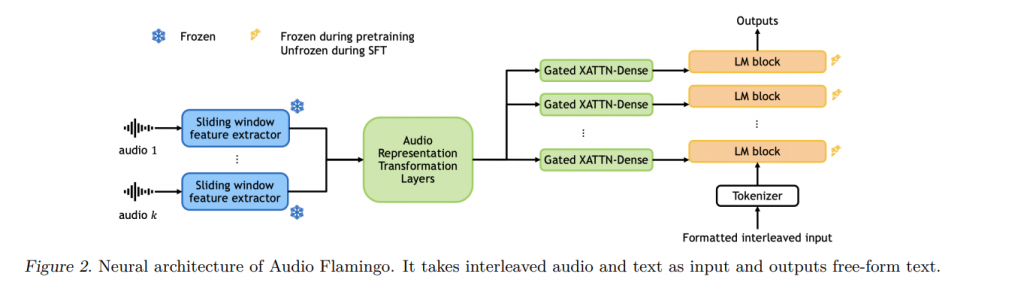
Модель використовує набори даних ICL та обчислює kNN на аудіо-вбудовуваннях для поліпшення процесів навчання та пошуку. Audio Flamingo демонструє вражаючі здібності до розуміння аудіо та здатність швидко адаптуватися до нових завдань завдяки контекстному навчанню та пошуку, встановлюючи нові стандарти в галузі.
)
)
)
)
)
)
)
)
