

09.11.2023 17:16
Компактна модель розпізнавання мовлення від дослідників з Hugging Face
Дослідники Hugging Face розробили новий метод розгортання великих попередньо навчених моделей розпізнавання мови на пристроях з обмеженими ресурсами. Вони створили великий набір мовних даних з відкритим вихідним кодом, використовуючи псевдомаркування, а потім використали цей набір даних для дистиляції зменшеної версії моделі Whisper, яка отримала назву Distil-Whisper.
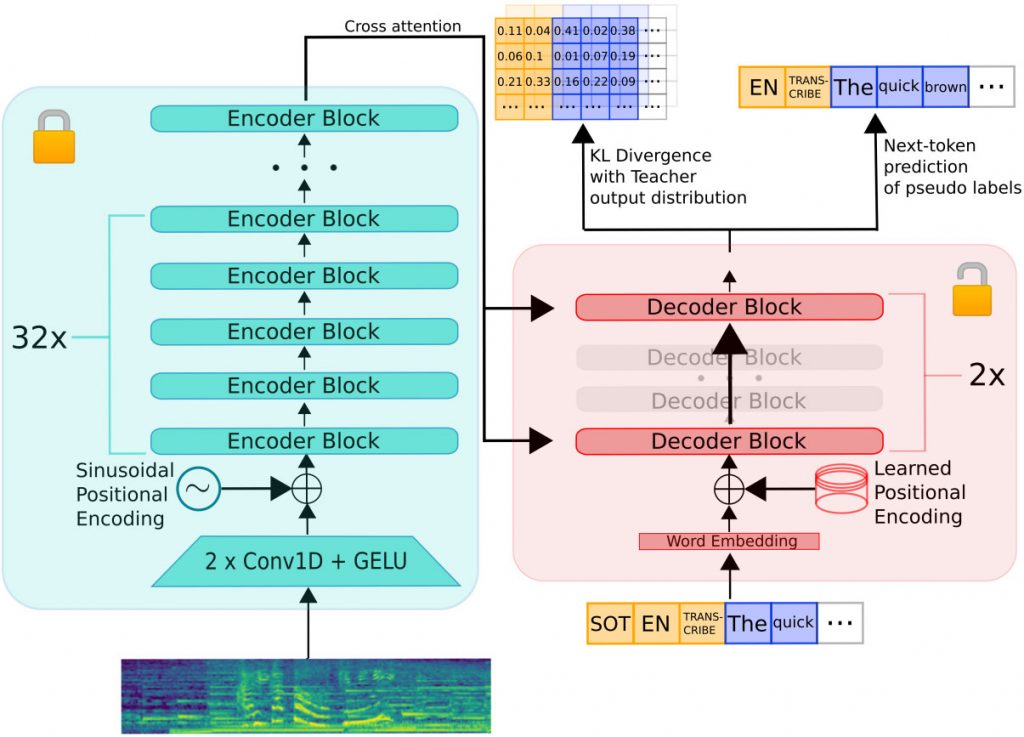
Distil-Whisper працює значно швидше і має менше параметрів, ніж оригінальна модель Whisper, зберігаючи при цьому стійкість до складних акустичних умов і здатність зменшувати помилки, пов’язані з галюцинаціями, при транскрипції довгих аудіозаписів. Це досягається за допомогою процесу дистиляції знань, який використовує псевдомаркування для створення синтетичного навчального набору даних для студентської моделі.
Дослідники також представили новий широкомасштабний метод псевдомаркування для мовних даних, який є перспективним напрямком для майбутніх досліджень у галузі дистиляції знань для розпізнавання мовлення.
)
)
)
)
)
)
)
)
