

10.01.2024 17:34
Дослідники з Microsoft та NU Singapore представили Cosmo
Мультимодальне навчання – це розробка систем, здатних інтерпретувати та обробляти різноманітні вхідні дані, включаючи як візуальну, так і текстову інформацію. Інтеграція різних типів даних через використання штучного інтелекту створює певні виклики, але водночас відкриває можливості для більш тонкого розуміння та обробки складних даних.
Важливим питанням у мультимодальному навчанні є ефективна інтеграція та кореляція різних форм даних, таких як текст, зображення чи відео. Мета полягає у створенні передових систем штучного інтелекту, які можуть інтерпретувати ці різноманітні типи даних одночасно, отримуючи корисні результати. Це завдання є ключовим для підвищення здатності ШІ розуміти світ і взаємодіяти з ним у більш людський спосіб.
Останні досягнення зосереджені на використанні великих мовних моделей (LLM) для обробки об’ємних текстових даних. Хоча ці моделі чудово справляються зі складними, змішаними даними, вони часто стикаються з обмеженнями в завданнях, що вимагають точного узгодження текстових і візуальних елементів. Щоб вирішити цю проблему, дослідники з Національного університету Сінгапуру та Microsoft Azure AI представили фреймворк COSMO (COntrastive Streamlined MultimOdal Model), що стало справжнім досягненням в обробці мультимодальних даних.
Фреймворк COSMO використовує інноваційний підхід до обробки мультимодальних даних, стратегічно розділяючи мовну модель на спеціалізовані сегменти, призначені для обробки як одномодального тексту, так і складних мультимодальних даних. Цей поділ має вирішальне значення для підвищення ефективності та продуктивності моделі в роботі з різними типами даних. COSMO вводить контрастну асиметрію до втрат мовної моделі в існуючих моделях, що є ключовою інтеграцією для покращення здатності моделі узгоджувати різні форми даних, особливо в задачах, пов’язаних з текстовими та візуальними даними.

Невід’ємною складовою методології COSMO є використання набору даних Howto-Interlink7M. Цей набір даних, провідний ресурс у цій галузі, надає детальні анотації до відеотекстових даних, заповнюючи критичну прогалину в доступності високоякісних наборів відеоданих з довгими текстами. Насиченість і повнота цього набору даних є надзвичайно важливими для покращення продуктивності моделі в задачах зображення-тексту.
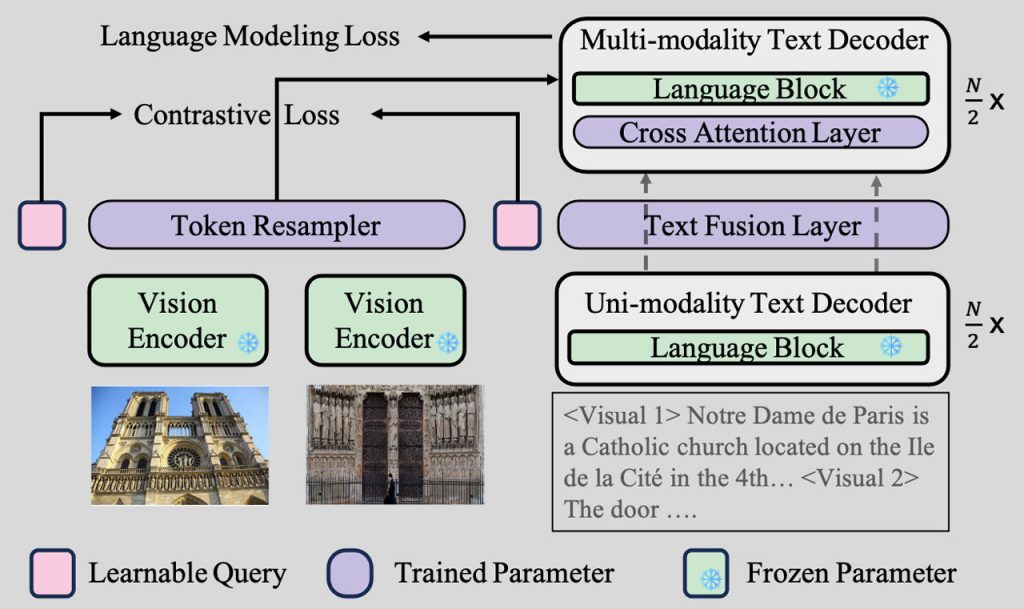
Продуктивність COSMO демонструє використання новітніх технологій та методології, демонструючи значні покращення порівняно з існуючими моделями, особливо в задачах, що вимагають узгодження текстових та візуальних даних. У конкретному завданні з підписом до 4-х фотографій Flickr COSMO суттєво покращила свої показники, збільшивши їх з 57,2% до 65,1%. Таке покращення підкреслює покращену здатність моделі розуміти та обробляти мультимодальні дані.
Підсумовуючи, ключові моменти цього дослідження включають:
- Впровадження COSMO, фреймворку для оптимізованої обробки мультимодальних даних;
- Стратегічне розділення мовної моделі на сегменти для обробки унімодального тексту і мультимодальних даних;
- Інтеграцію втрат контрастності з втратами мовної моделі для покращення можливостей вирівнювання даних;
- Розробку і використання набору даних Howto-Interlink7M, що є важливим доповненням до наборів мультимодальних даних з довгим текстом.
- Помітне покращення продуктивності COSMO у вирівнюванні текстових і візуальних даних демонструє його розширені можливості мультимодального навчання.
)
)
)
)
)
)
)
)
